



Vollständig anpassbare Server-Lösungen
Mit über 1500 Basissystemen, die darauf warten, angepasst zu werden, bietet Novarion eine riesige Auswahl an Serversystemen, die den Bedarf von kleinen Unternehmen bis hin zu Hochleistungsrechnern in Bereichen wie künstliche Intelligenz oder Quantencomputing abdecken.
HQC 4020 - 8-Wege-Hochleistungssystem
Der hybride Quanten-Hochleistungsrechner von Novarion besticht nicht nur durch seine hohe Leistung, sondern auch durch die softwaredefinierten Qbits, die es Kunden ermöglichen, Quantencomputer-Software zu entwickeln und deren Effektivität und Effizienz zu testen. Darüber hinaus ermöglicht die implementierte Berechnungslogik, dass die von Ihnen entwickelte Quantencomputer-Software auf zukünftigen nativen Quantencomputern läuft, was innovativen Kunden einen erheblichen Vorsprung verschafft.
Erstellen Sie Ihren eigenen Server mit unserem Endkundenkonfigurator und erhalten Sie in Kürze ein Angebot.
*Aufgrund der aktuellen Chipkrise können sich die Preise und die Verfügbarkeit von Komponenten ändern. Für weitere Informationen und technische Unterstützung wenden Sie sich bitte an unsere Systemarchitekten über das Kontaktformular (unten auf der Seite) oder per Telefon.


AMD basierte Server
- CPU Dual AMD Epyc bis zu 64 Cores per CPU
- RAM Bis zu 8TB DDR4 3200Mhz
- Size Bis zu 8 Units (Twin Server)
Die AMD EPYC™ 7003 Prozessoren basieren auf den x86-Architekturinnovationen der rekordverdächtigen EPYC 7002 Prozessoren und sind der neue Standard für das moderne Rechenzentrum1. Mit hohen Frequenzen, hohen Kernzahlen, hoher Speicherbandbreite und -kapazität und bis zu 32 MB L3-Cache pro Kern ermöglichen die AMD EPYC 7003 Prozessoren eine außergewöhnliche HPC-Leistung.
Intel basierte Server
- CPU Dual Intel Xeon Platinum bis zu 56 Cores per CPU
- RAM Bis zu 4TB DDR4 3200MHz für Dual-CPU-Systeme
- Size Bis zu 8 Units (Twin Server)

Skalierbare Intel® Xeon® Prozessoren bieten branchenführende, für Arbeitslasten optimierte Leistungsmerkmale mit integrierter KI-Beschleunigung. Sie bieten eine perfekt abgestimmte Leistungsgrundlage, um die transformative Wirkung von Daten vom Netzwerkrand bis zur Cloud zu beschleunigen.
NOVARION's HQC-4020
- CPU 8x Intel® Xeon® Platinum 8260
- RAM 12TB, 2933 MHz (up to 24 TB)
- Size 8 Units

Skalierbare Intel® Xeon® Prozessoren bieten branchenführende, für Arbeitslasten optimierte Leistungsmerkmale mit integrierter KI-Beschleunigung. Sie bieten eine perfekt abgestimmte Leistungsgrundlage, um die transformative Wirkung von Daten vom Netzwerkrand bis zur Cloud zu beschleunigen.




Leistungsstarke GPU-basierte Systeme
Mit Novarions Hochleistungs-GPU-Servern können Sie Ihre anspruchsvollsten HPC- und Hyperscale-Workloads im Rechenzentrum beschleunigen. Datenwissenschaftler und Forscher können jetzt Datensätze im Petabyte-Bereich viel schneller analysieren als mit herkömmlichen CPUs.
Die Anwendungen reichen von der Energieforschung bis zum Deep Learning.
NVIDIA-Grafikprozessoren bieten eine enorme Leistung, um umfangreichere Simulationen schneller als je zuvor zu berechnen. Darüber hinaus liefern NVIDIA-GPUs die höchste Leistung für virtuelle Desktops, Anwendungen, Workstations und unterstützen eine hohe Benutzerdichte.
GPU T.I. System
Für die anspruchsvollsten Workloads baut Supermicro die leistungsstärksten und schnellsten Systeme, die auf NVIDIA A100™ Tensor Core GPUs basieren. Supermicro unterstützt eine Reihe von Kundenanforderungen mit optimierten Systemen für die neuen HGX™ A100 8-GPU und HGX™ A100 4-GPU Plattformen. Mit der neuesten Version der NVIDIA® NVLink™- und NVIDIA NVSwitch™-Technologien können diese Systeme eine Leistung von bis zu 5 PetaFLOPS in einem einzigen 4U-System liefern.
T.I - Technological Intelligence
Wir schlagen den neuen Begriff T.I. anstelle von A.I. vor, da sowohl technologische als auch biologische (menschliche) Intelligenz im Grunde das Ergebnis der Schaffung und Ausführung von intrinsischen Algorithmen in einem Informationsverarbeitungssystem ist.
Unserer Ansicht nach ist die zugrundeliegende Hardware eines solchen intelligenten Systems zweitrangig und qualifiziert nicht die Natur der Intelligenz selbst.

NVIDIA NVLink

Quelle: https://www.nvidia.com/de-de/data-center/nvlink/
NVIDIA® NVLink® ist eine direkte Hochgeschwindigkeitsverbindung zwischen GPUs. NVIDIA NVSwitch™ hebt die Interkonnektivität auf die nächste Stufe, indem es mehrere NVLinks integriert, um eine All-to-All-GPU-Kommunikation mit voller NVLink-Geschwindigkeit innerhalb eines einzelnen Knotens wie dem NVIDIA HGX™ A100 zu ermöglichen.
Mit der Kombination aus NVLink und NVSwitch war NVIDIA in der Lage, die KI-Leistung über mehrere GPUs hinweg effizient zu skalieren und MLPerf 0.6 zu gewinnen – den ersten branchenweiten KI-Benchmark.
NVIDIA NVSwitch

Quelle: https://www.nvidia.com/de-de/data-center/nvlink/
Mit der rasanten Verbreitung von Deep Learning ist auch der Bedarf an schneller und skalierbarer Vernetzung gestiegen. Dies liegt daran, dass sich die PCIe-Bandbreite bei Multi-GPU-Systemen oft als Engpass erweist. Die Skalierung von Deep-Learning-Workloads erfordert eine deutlich höhere Bandbreite und geringere Latenzzeiten.
NVIDIA NVSwitch stützt sich auf die fortschrittliche Kommunikationsfähigkeit von NVLink, um dieses Problem zu lösen. Für eine noch höhere Deep Learning-Leistung unterstützt eine GPU-Fabric mehrere GPUs auf einem einzigen Server, die über Verbindungen mit voller Bandbreite miteinander vernetzt sind. Jede GPU verfügt über 12 NVLinks zum NVSwitch, um eine Hochgeschwindigkeits-Rundumkommunikation zu ermöglichen.

Quelle: https://www.nvidia.com/de-de/data-center/a100/
Hochleistungs-Computing - Nvidia A100
Um die nächste Generation von Entdeckungen zu erschließen, setzen Wissenschaftler auf Simulationen, um die Welt um uns herum besser zu verstehen.
NVIDIA A100 führt Tensor Cores mit doppelter Präzision ein und stellt den größten Leistungssprung für HPC seit der Einführung von GPUs dar. In Kombination mit 80 GB des schnellsten Grafikspeichers können Forscher eine zuvor 10-stündige Simulation mit doppelter Genauigkeit auf dem A100 auf weniger als vier Stunden reduzieren. Auch HPC-Anwendungen können TF32 nutzen, indem sie einen bis zu 11-mal höheren Durchsatz bei dichten Multiplikationsaufgaben mit Einzelpräzision erreichen.
Für HPC-Anwendungen mit großen Datensätzen bietet der zusätzliche Speicher des A100 80 GB eine bis zu zweifache Steigerung des Durchsatzes. Der massive Speicher und die unübertroffene Speicherbandbreite machen den A100 80 GB zur idealen Plattform für Workloads der nächsten Generation.
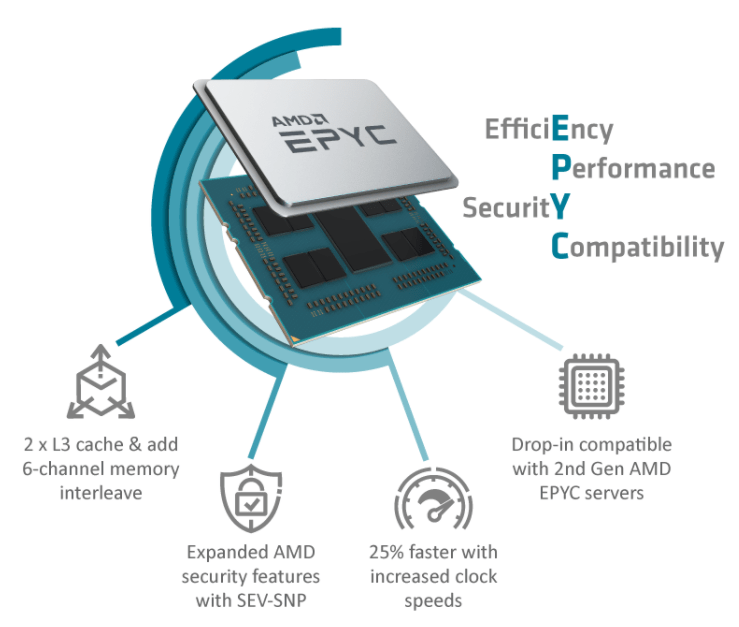
Über AMD Epyc
Die AMD EPYC™ 7003 Prozessoren basieren auf den x86-Architekturinnovationen der rekordverdächtigen EPYC 7002 Prozessoren und sind der neue Standard für das moderne Rechenzentrum. Mit hohen Frequenzen, hohen Kernzahlen, hoher Speicherbandbreite und -kapazität und bis zu 32 MB L3-Cache pro Kern ermöglichen die AMD EPYC 7003 Prozessoren eine außergewöhnliche HPC-Leistung.
Neben der hohen Speicherbandbreite, die durch die Unterstützung von 8 Kanälen mit DDR4-3200-Speicher erreicht wird, synchronisieren die EPYC 7003-Prozessoren auch den Takt der Data Fabric mit den Taktraten des Speichers, was sowohl die Speicherbandbreite als auch die Latenzzeit weiter verbessert. Die Unterstützung von bis zu 4 TB Speicher pro Sockel verbessert die Fähigkeit, sehr große Datensätze zu verarbeiten. Der besonders große L3-Cache, der bis zu 256 MB pro CPU und bis zu 32 MB pro Kern erreicht, trägt zur effizienten Nutzung von bis zu 64 Kernen pro CPU bei.


Quanton HGX Plaform Übersicht
Ideal für groß angelegte Deep-Learning-Trainings- und Neuronalnetz-Modellanwendungen. Das neue 4U-GPU-System verfügt über das NVIDIA HGX A100 8-GPU-Baseboard, bis zu sechs NVMe U.2 und zwei NVMe M.2, 10 PCI-E 4.0 x16 I/O, mit Supermicros einzigartiger AIOM-Unterstützung, die die 8-GPU-Kommunikation und den Datenfluss zwischen Systemen durch die neuesten Technologie-Stacks wie NVIDIA NVLink und NVSwitch, GPUDirect RDMA, GPUDirect Storage und NVMe-oF auf InfiniBand stärkt.

Unerreichte End-to-End-Plattform für beschleunigtes Computing
NVIDIA HGX repräsentiert die weltweit leistungsstärksten Server mit NVIDIA A100 Tensor Core GPUs und Hochgeschwindigkeits-Interconnects. Mit 16 A100-GPUs bietet HGX A100 bis zu 1,3 Terabyte (TB) Grafikspeicher und eine Speicherbandbreite von über 2 Terabyte pro Sekunde (Tb/s), wodurch eine noch nie dagewesene Beschleunigung erreicht wird.
Im Vergleich zu früheren Generationen bietet HGX eine bis zu 20-fache KI-Beschleunigung mit Tensor Float 32 (TF32) und HPC eine 2,5-fache Beschleunigung mit FP64. NVIDIA HGX leistet atemberaubende 10 petaFLOPS und ist damit die leistungsstärkste beschleunigte und vertikal skalierbare Serverplattform für KI und HPC.
Das HGX wurde ausgiebig getestet und ist einfach zu installieren. Die Integration mit Partnerservern garantiert eine hohe Leistung. Die HGX-Plattform ist sowohl als 4-GPU- als auch als 8-GPU-HGX-Motherboard mit SXM-GPUs erhältlich. Sie ist auch als PCIe-GPUs für eine modulare Einsatzoption erhältlich, die höchste Rechenleistung auf Mainstream-Servern bietet.
HGX A100 Technical Spezifikationen
NVIDIA HGX ist als einzelnes Motherboard mit vier oder acht A100-GPUs erhältlich, jeweils mit 40 GB oder 80 GB GPU-Speicher. Die 4-GPU-Konfiguration ist vollständig mit NVIDIA NVLink® verbunden, und die 8-GPU-Konfiguration ist über NVSwitch miteinander verbunden. Zwei NVIDIA HGX A100 Motherboards können mit NVSwitch Interconnect kombiniert werden, um einen leistungsstarken Einzelknoten mit 16 GPUs zu bilden.
HGX ist auch in einem PCIe-Formfaktor als einfach einzurichtende Option erhältlich, die höchste Rechenleistung auf Mainstream-Servern mit jeweils 40 GB oder 80 GB GPU-Speicher bietet.
Diese leistungsstarke Kombination aus Hardware und Software bildet die Grundlage für die ultimative KI-Supercomputing-Plattform.

Quelle: https://www.nvidia.com/de-de/data-center/a100/
Source: https://www.nvidia.com/de-de/technologies/cuda-x/
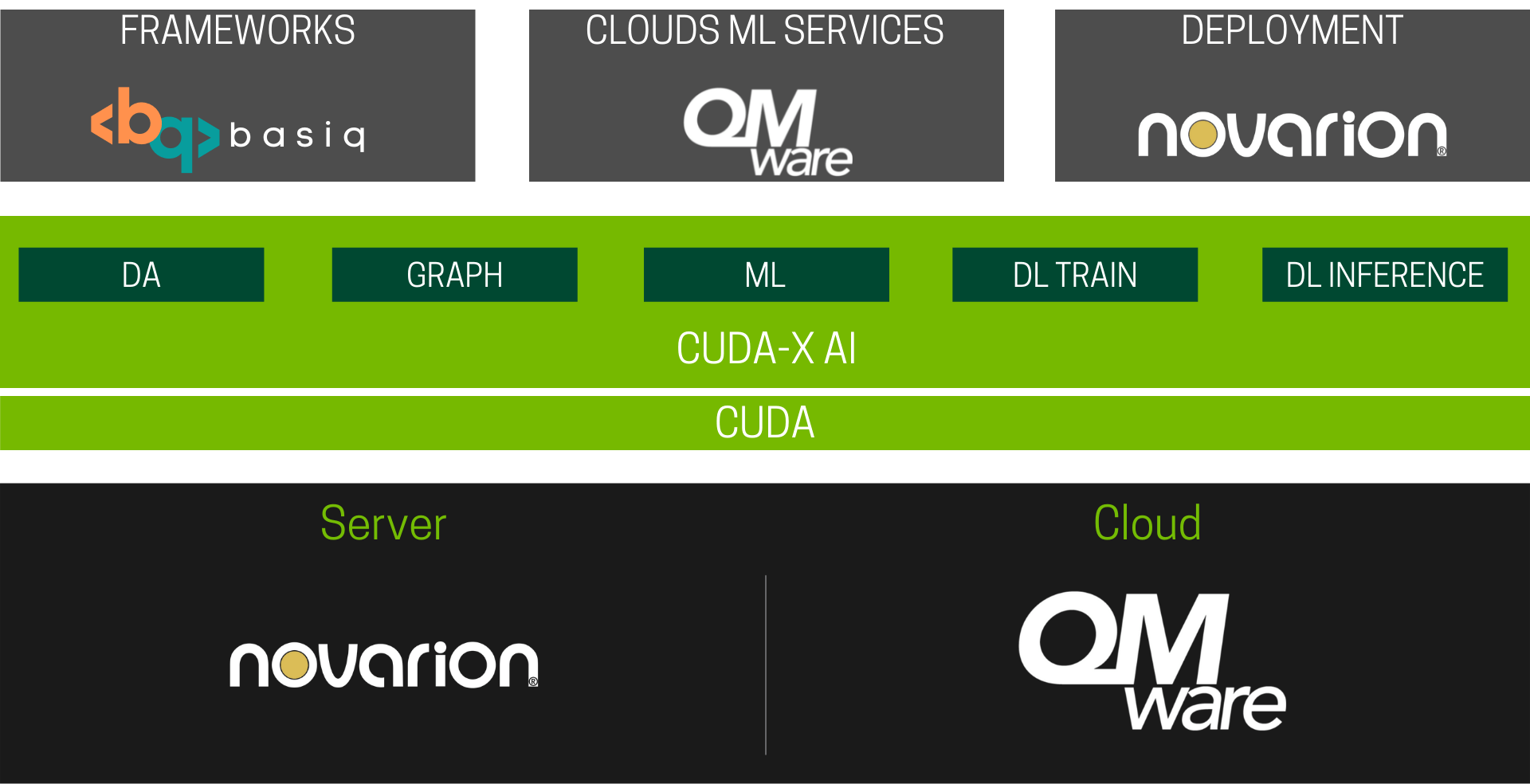
NVIDIA-CUDA-X
GPU-beschleunigte Bibliotheken für KI und HPC.
Entwickler, Forscher und Erfinder in einer Vielzahl von Bereichen nutzen die GPU-Programmierung, um ihre Anwendungen zu beschleunigen. Die Entwicklung dieser Anwendungen erfordert eine robuste Programmierumgebung mit hoch optimierten, domänenspezifischen Bibliotheken. NVIDIA CUDA®-basiert NVIDIA CUDA-X ist eine Sammlung von Bibliotheken, Tools und Technologien, die in zahlreichen Anwendungsbereichen - von künstlicher Intelligenz bis hin zu High-Performance-Computing - eine deutlich höhere Leistung als Alternativen bieten.
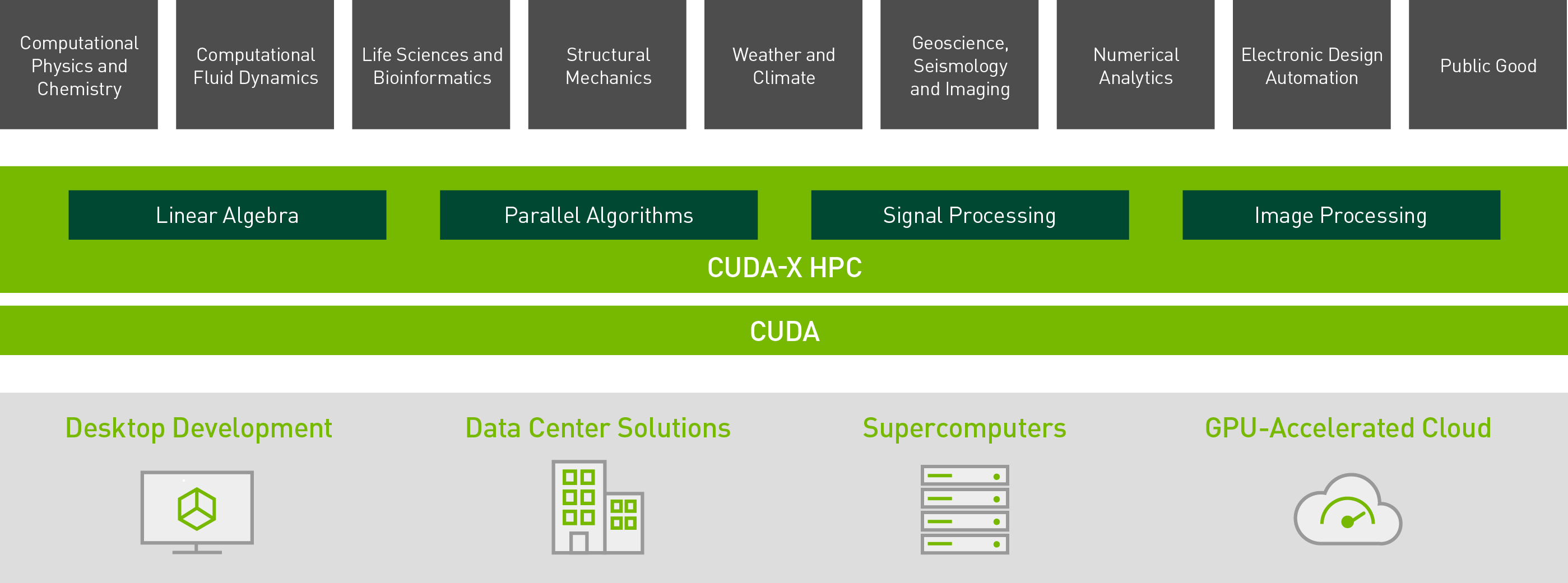
CUDA X HPC
HPC-Anwendungen umfassen viele Bereiche, von der Strömungsdynamik bis zur Wettersimulation. CUDA-X HPC ist eine Sammlung von Bibliotheken, Tools, Compilern und APIs, die Entwicklern helfen, die komplexesten Probleme der Welt zu lösen. CUDA-X HPC enthält hochoptimierte Kernel, die für High-Performance-Computing (HPC) unerlässlich sind. GPU-beschleunigte Bibliotheken für lineare Algebra, parallele Algorithmen sowie Signal- und Bildverarbeitung bilden die Grundlage für rechenintensive Anwendungen in Bereichen wie Computerphysik, Chemie, Molekulardynamik und seismische Exploration.
Source: https://www.nvidia.com/de-de/technologies/cuda-x/
*Die abgebildeten Systeme dienen als Basis und können als Beispielsystem betrachtet werden.
Je nach gewünschter Konfiguration bieten wir maßgeschneiderte Systeme an, die genau Ihren Vorstellungen entsprechen.
Wenn Sie Fragen zu den Systemen oder spezifischere Anforderungen haben, nutzen Sie bitte das untenstehende Kontaktformular.

Übersicht
– Unterstützung von Root of Trust auf Hardware-Ebene
– 2U – 4 Knoten Front-Access-Server-System
– Zwei AMD EPYC™ Prozessoren der 7003-Serie
– 8 x LGA 4094 Sockel – 8-Kanal RDIMM/LRDIMM DDR4 pro Prozessor, 128 x DIMMs
– 8 x 1Gb/s LAN-Anschlüsse (Intel® I350-AM2)
– 4 x Dedizierte Verwaltungsanschlüsse
– 2 x globaler CMC-Verwaltungsanschluss
– 8 x 2,5″-Gen4-NVMe-SSD-Einschübe mit Hot-Swap-Funktion
– 8 x M.2 mit PCIe Gen4 x4 Schnittstelle
– 4 x Low Profile PCIe Gen4 x16 Erweiterungssteckplätze
– 4 x OCP 3.0 Gen4 x16 Mezzanine-Steckplätze
– Dual 3200W (240V) 80 PLUS Platinum redundantes Netzteil
Beabsichtigte Nutzung von HPC Cluster
High-Performance-Computing (HPC)-Cluster werden zur Bearbeitung von Rechenaufgaben eingesetzt. Diese Rechenaufgaben werden auf mehrere Knotenpunkte verteilt.
Entweder werden die Aufgaben in verschiedene Pakete aufgeteilt und parallel auf mehreren Knoten ausgeführt oder die Rechenaufgaben (Jobs genannt) werden auf die einzelnen Knoten verteilt.
Die Verteilung der Aufträge wird in der Regel von einem Auftragsverwaltungssystem übernommen. HPC-Cluster sind häufig im wissenschaftlichen Bereich zu finden. In der Regel sind die einzelnen Elemente eines Clusters über ein schnelles Netz miteinander verbunden. Auch so genannte Renderfarmen fallen in diese Kategorie.
Technische Seite des HPC-Clusters
In HPC-Clustern wird die zu erledigende Aufgabe, der „Job“, häufig mit Hilfe eines Zerlegungsprogramms in kleinere Teile zerlegt und dann auf die Knoten verteilt.
Die Kommunikation zwischen Jobteilen, die auf verschiedenen Knoten laufen, erfolgt in der Regel über Message Passing Interface (MPI), da eine schnelle Kommunikation zwischen den einzelnen Prozessen gewünscht ist. Dazu koppelt man die Knoten mit einem schnellen Netzwerk wie InfiniBand.
Eine gängige Methode zur Verteilung von Aufträgen auf einen HPC-Cluster ist ein Job-Scheduling-Programm, das die Verteilung nach verschiedenen Kategorien, wie Load Sharing Facility (LSF) oder Network Queueing System (NQS), vornehmen kann.
Mehr als 90 % der TOP500-Supercomputer sind Linux-Cluster, nicht zuletzt weil billige COTS-Hardware für anspruchsvolle Rechenaufgaben verwendet werden kann.


Sofort verfügbare Systeme Übersicht
Auf der folgenden Seite finden Sie Serversysteme, deren Komponenten sofort verfügbar sind und auf Anfrage bestellt werden können. Natürlich ist es möglich, diese Systeme bei Bedarf anzupassen. Wenn Sie spezielle Wünsche haben und Änderungen an diesen Systemen vornehmen möchten, kontaktieren Sie uns bitte über das untenstehende Kontaktformular. Unsere Systemarchitekten helfen Ihnen gerne weiter.

Rackmount-Gehäuse 2U
Chipset: Intel® C621A (Ice Lake) Chipset, IPMI Fernwartung mit voller Funktion integriert
CPU: Intel® Xeon® Silver 4310 • 2.10(3.30)GHz • S4189 • 18MB • 12C/24T • 2666MHz • 2xUPI • 120W • max. 6TB
Hauptspeicher: DIMM 16GB DDR4 • 3200MHz • ECC • Registered • SRx4 • 1.2V (Premium-geprüfte A-bin-Paket-Chips für optimierte Leistung)
Controller: Broadcom SAS-3: // Broadcom 9460-8i PCI-E 3.1 (x8) SAS-3/NVME Controller • 2GB • 8-port (8i) • RAID 0/1/5/6/10/50/60 • LP
Hot-Swap SATA SSDs: 480GB SSD • 2.5“ • 3D TLC • 7mm • SATA-3 • 1.3DWPD/3Y

Rackmount-Gehäuse 4U
Chipset: Intel® C621A (Ice Lake) chipset, IPMI Fernwartung mit voller Funktion integriert
CPU: Intel® Xeon® Silver 4310 • 2.10(3.30)GHz • S4189 • 18MB • 12C/24T • 2666MHz • 2xUPI • 120W • max. 6TB
Hauptspeicher: DIMM 16GB DDR4 • 3200MHz • ECC • Registered • SRx4 • 1.2V• 1.2V (Premium-geprüfte A-bin-Paket-Chips für optimierte Leistung)
Controller: Broadcom SAS-3: // Broadcom 9460-8i PCI-E 3.1 (x8) SAS-3/NVME Controller • 2GB • 8-port (8i) • RAID 0/1/5/6/10/50/60 • LP
Hot-Swap SATA SSDs: 18TB Festplatte • SATA-3 • 7.200rpm • RE • 512e/4kn • Helium

Rackmount-Tower-System 4U
Chipset: Intel® C621A (Ice Lake) chipset, IPMI Fernwartung mit voller Funktion integriert
CPU: Intel® Xeon® Silver 4310 • 2.10(3.30)GHz • S4189 • 18MB • 12C/24T • 2666MHz • 2xUPI • 120W • max. 6TB
Hauptspeicher: DIMM 16GB DDR4 • 3200MHz • ECC • Registered • SRx4 • 1.2V (Premium-geprüfte A-bin-Paket-Chips für optimierte Leistung)
Controller: Broadcom SAS-3: // Broadcom 9460-8i PCI-E 3.1 (x8) SAS-3/NVME Controller • 2GB • 8-port (8i) • RAID 0/1/5/6/10/50/60 • LP
Hot-Swap SATA SSDs: 480GB SSD • 2.5“ • 3D TLC • 7mm • SATA-3 • 1.3DWPD/3Y
Jetzt Innovation erleben – Lassen Sie sich individuell beraten!
„Ob High-Performance-Server, Quantum Computer oder AI-Lösungen – wir finden gemeinsam das passende Produkt für Ihr Unternehmen.“
Ihr Kontakt für NOVARION Produkte:

Novara
Virtual Assitant
E-Mail: novara@novarion.ai
HP: novarion.ai